Basically it ended up in a kind of finger pointing between the application vendor and the IT DBA / storage admins, one side saying that the infrastructure used offers insufficient I/O capabilities (since the most important application tasks where dominated by I/O waits in the database), and the other side saying that the application doesn't make use of the I/O capabilities offered - compared to other databases / applications that showed a significantly higher IOPS rate and/or I/O throughput using the same kind of storage.
At the end it turned out that in some way both sides were right, because the application made use of a somewhat unusual configuration for batch processing: Due to very slow Dedicated Server connection establishment that slowed down some other, more interactive part of the application, the database and client connection strings were configured to use Shared Server connections by default for all parts of the application. This successfully solved the connection establishment problem but obviously introduced another, so far not recognized problem.
Using my recently published I/O benchmark we performed some tests to measure the maximum IOPS and throughput of that specific database independently from the application, and the results were surprising, because in particular the test variations that were supposed to perform asynchronous physical read single block ("db file parallel read") and multi block I/O ("direct path read") didn't do so, but showed synchronous I/O only ("db file sequential read" / "db file scattered read").
After some investigations it became obvious the reason for this behaviour was the usage of the Shared Server architecture - simply switching to Dedicated Server sessions showed the expected behaviour and also a significantly higher maximum IOPS rate and I/O throughput at the same level of concurrency.
It's very easy to reproduce this, using for example my read IOPS and throughput benchmark scripts and performing the benchmark using either Shared or Dedicated Server architecture in asynchronous I/O mode.
For example, this is what I get running this on my laptop using Dedicated Server and testing maximum read I/O throughput in asynchronous I/O mode (which should result in "direct path read" operations bypassing the buffer cache):


If I repeat exactly the same test (same settings, number of processes, size of objects etc.) using Shared Server architecture, this is what I get:
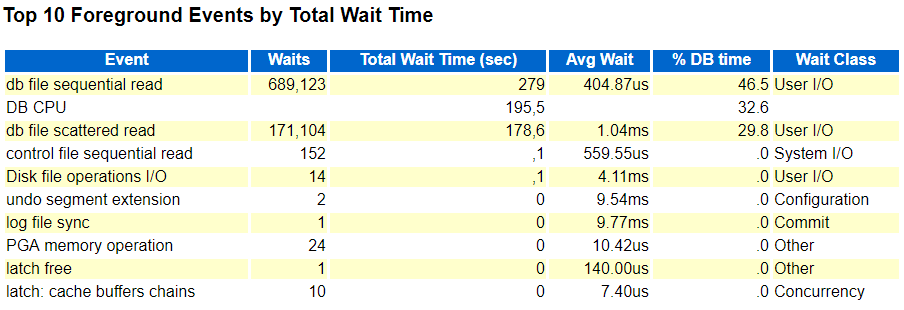

This is particularly interesting - no direct path reads although the benchmark sessions set in this case "_serial_direct_read" = 'always'.
In principle the same can be seen when running the maximum read IOPS benchmark, here is the expected result when using Dedicated Servers in asynchronous I/O mode:


And again, this is what I get when running the same test using Shared Servers:


Again no sign of asynchronous I/O ("db file parallel read") - and the achieved IOPS rate is significantly lower, which is exactly what the client experienced, much more DB time waiting for I/O and less time spent on CPU than expected. Depending on the particular storage configuration and latency the difference when using the same number of processes can be even more significant, I've seen up to factor 20 difference in achieved IOPS rate, and factor 3 to 4 is quite typical. Of course as usual how relevant this really is all depends on the actual query, execution plan and data pattern and where most of the time is spent.
Also, it is important to point out that all this might not be too relevant to most configurations, since Shared Servers aren't used that much nowadays in the times of application servers / connection pools dominating typical environments. Also it's probably rather uncommon to use Shared Servers for batch processing tasks like this client did.
Although Shared Servers were originally designed for typical OLTP applications having many open sessions being idle most of the time and performing mostly very simple and straightforward operations (like looking up a few rows via an efficient index access path) it's still interesting to see this limitation that can be quite significant depending on the I/O patterns used. So far I've not seen this documented anywhere, also on MyOracleSupport I couldn't find any matching notes describing the behaviour, and unfortunately no Service Request was opened for the issue yet.
When using Parallel Execution, by the way, which is also very unlikely when using Shared Servers but perfectly possible (the Shared Server session then acts as Query Coordinator), the Parallel Servers can make use of asynchronous I/O - so the limitation only seems to apply to the Shared Server session itself. I can think of some reasons why this limitation could be explained from an implementation point of view the way Shared Servers work, but this is of course only speculation.
All currently relevant versions show the same behaviour in that regard, by the way. I've reproduced this on 11.2.0.4, 12.1.0.2 and 12.2.0.1 on Windows as well as on Linux.


Just a theory, thinking loud:
ReplyDeleteDedicated Server: Blocks from direct path reads go to PGA. Once they were put into PGA, can be reused for other SQL statements by the same session? I do not know how it works, but if yes, then in MTS, they have to go to UGA to be reused by the same session, because the session can uses any process.
If so, then the blocks from Direct Path Reads occupied SGA as the UGA in MTS is in Large Pool.
If it occupies the Large Pool, so why not to put it into Buffer Cache? It is still in SGA, but better re-usability as i can be then reused by other sessions too.
So in MTS, if it has to go to SGA, better re-usability is in the Buffer Cache than in the Large pool.
Hi Jan,
ReplyDeleteI don't think that blocks put into the PGA by direct path reads get re-used by other SQL statements of the same session. If they were then I would see some rationale behind your theory.
However all this doesn't apply to the case of single block reads that go into the buffer cache anyway (synchronous "db file sequential read" vs asynchronous "db file parallel read") - so to me it looks more like an either incomplete implementation or some complications in the handling of the asynchronous I/O calls when using the Shared Server code path / architecture.
Randolf